Caso 6 – Business Intelligence

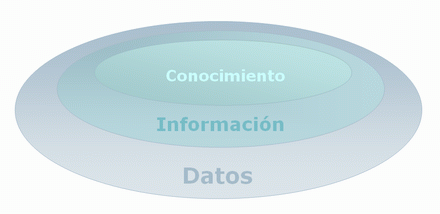
A lo largo de este blog, hemos estado reflexionando y contando varios temas acerca de sistemas de búsqueda de información, recuperación de la información, lenguajes de programación, bases de datos, etc. Es decir, hemos estado reflexionando sobre un concepto clave: la información.
Para recordar un poco lo visto anteriormente, ya que tiene
mucha importancia para el tema que trataremos a continuación, en el mundo
empresarial se trabajan con datos (la unidad mínima) que por sí solos no
pueden aportar nada. Estos datos, una vez son analizados y puestos en un
contexto y un propósito determinado se puede convertir en información,
que podrá ser utilizada par en varios fines. El conjunto de informaciones, que
extraemos de muchos datos, unidos con la experiencia entre otras variables, se
convierte en conocimiento, que permite a las empresas, y también a las
personas, tomar decisiones importantes.
¿Es importante
conocer muchos datos para tomar nuestras decisiones?
A lo largo de nuestra vida, sucede en muchas ocasiones que
tenemos que decidir entre varias opciones para tomar una decisión
determinada. Para ello, lo que hacemos es seguir un proceso determinado que
ayude a elegir la opción adecuada. Por ejemplo, si decidimos comprar un
ordenador de mesa tendremos que pensar en varias posibilidades que se nos
presentan: el precio que disponemos, los componentes de nuestro equipo (CPU, GPU,
etc.), las tiendas donde podamos adquirirlo, el sistema operativo, etc. Cuanto
más datos e información tengamos a nuestra disposición, más
posibilidades tendremos de cumplir nuestro objetivo.
 |
| Proceso para resolver un problema |
Si analizamos más a fondo los pasos que utilizamos
para resolver un problema, nos damos cuenta que lo primero que hacemos es observar
el problema que se nos plantea. Después, analizamos el problema en base
a los datos que tenemos. A continuación, tomamos la decisión que más se ajusta
a nuestras necesidades. Por último, ejecutamos la opción elegida.
Ahora, pongámonos el “casco de pensar”, si nosotros mismos,
que somos personas “corrientes”, tenemos muchas variables y datos para decidir tan
cosas elementales, como comprar un ordenador o elegir una carrera universitaria,
imaginemos el increíble volumen de datos y variables que podrá manejar una mediana
o gran empresa para tomar sus decisiones.
¿Existe algún sistema
que permita darnos una respuesta para tomar nuestras decisiones?
Las empresas utilizan una serie de programas y herramientas que
permiten obtener información o conocimiento partiendo de diversos datos. Este
conocimiento les permita tomar las decisiones más adecuadas en función a sus
problemas.
¿Qué ventajas aportan estos sistemas? Lo más
importante es que aportan mucha información y conocimiento en muy poco
tiempo, lo que permite tomar decisiones sin perder demasiado tiempo. Además,
ya que se tienen en cuenta una cantidad enorme de datos, y han sido trabajados
y analizados, provoca que la información
o el conocimiento obtenido sea muy fiable.
 Para que estos sistemas puedan ser funcionales, y ayuden a
una empresa y organización deben cumplir unos requisitos muy específicos,
además de los mencionados anteriormente. Los datos con los que se
trabajan deben ser fiables y tener un fundamento. El sistema tiene que
ser eficiente y sus resultados deben ayudar a la empresa a tomar
decisiones. El precio no debe ser elevado, especialmente en tiempos de
crisis.
Para que estos sistemas puedan ser funcionales, y ayuden a
una empresa y organización deben cumplir unos requisitos muy específicos,
además de los mencionados anteriormente. Los datos con los que se
trabajan deben ser fiables y tener un fundamento. El sistema tiene que
ser eficiente y sus resultados deben ayudar a la empresa a tomar
decisiones. El precio no debe ser elevado, especialmente en tiempos de
crisis.
Si deseáis obtener más información con respecto a los
sistemas de información, ver sus ventajas, sus características, los tipos que
hay, etc., Podéis acceder a este pdf donde encontréis dicha información: https://dl.dropboxusercontent.com/u/50082027/tm0.pdf
Estos sistemas de toma de decisiones parecen bastante
complejos y su utilidad para que sea exclusiva en empresas. Entonces, nosotros,
los usuarios no técnicos, ¿podemos aprovecharnos de sus funcionalidades?
Si, de hecho los utilizamos muy habitualmente para resolver nuestros problemas,
aunque no nos demos cuenta de ello.
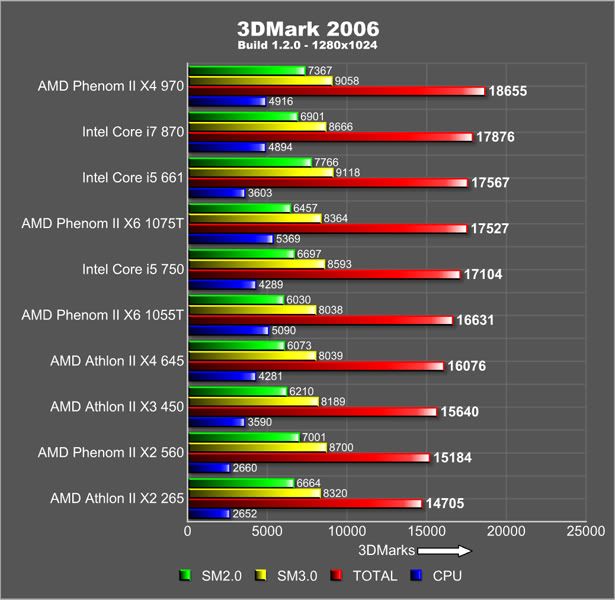 |
| Ejemplo de análisis de procesadores |
Por ejemplo, partiendo del ejemplo que he expuesto anteriormente,
si deseamos comprarnos un ordenador, un aspecto clave serán sus componentes. Para
ver si un componente es adecuado nos fijaremos en el análisis de dicho
componente realizado en webs específicas, donde han podido comparar varios
componentes similares teniendo en cuenta sus especificaciones, y nos muestran
las mejores opciones. En esta web podemos ver cómo nos muestras los
procesadores más potentes: http://www.solonotebooks.net/processors/
Estos sistemas nos hacen la vida más fácil a todo nosotros, y
ayudan de manera increíble a las grandes empresas para realizar operaciones
internacionales, ver los resultados de sus productos, los efectos del
marketing, etc.
¿Cómo se llaman estos
sistemas?
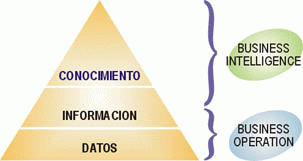
En el ámbito empresarial, estos sistemas se denominan Business
Intelligence (en español, inteligencia empresarial, aunque no se utiliza
mucho este término). Estos sistemas permiten transformar los datos en
información y la información en conocimiento, todo el proceso se realiza de
forma rápida y sencilla, tan solo se necesita introducir una serie de
condiciones en el programa para mostrarnos los resultados.
Estos sistemas son bastante complejos para montarlos en las
empresas, por ese motivo solo se utilizan en empresas medianas o grandes. Su instalación
necesita mucho tiempo, ya que para funcionar se necesitan “conectar” los
datos propios de las bases de datos de la empresa, además de otros datos
externos, que pueden provenir de empresas afiliadas, del ministerio, etc.
Para que entendáis esto, os voy a poner un breve ejemplo. Si
una empresa está dudando en despedir personal, tendrá que utilizar datos
internos, como el capital de la empresa, el número de trabajadores, el
rendimiento de los empleados, número de equipos, etc. Y otros datos externos,
como el dinero que ha de pagar por las indemnizaciones de despido, el I.V.A. etc.
Su configuración tampoco es sencilla, aunque no requiere
de personal informático para manejar estos dispositivos. Por medio
de una serie de clases se puede llegar a aprender su funcionamiento. Además, las
personas que trabajen con dichas maquinas, deben tener conocimientos de los
datos que están manejando.
Podéis encontrar más información, acerca de las
características básicas del Business Intelligence, en esta página web: http://www.sinnexus.com/business_intelligence/
¿Todos los Bussines Intelligence son iguales? No, hay
varios tipos de Business Intelligence, adaptados a las necesidades de las
empresas y del personal que lo maneja. Algunos sistemas están adaptados a los
ejecutivos que necesitan ver datos, convertidos en conocimiento, de forma
rápida en sus dispositivos, otros sirven para realizar consultas entre personas
expertas en un mismo área, etc. No voy a profundizar mucho en este aspecto, ya
que la explicación puede ser muy tediosa y creo que no es muy productivo explicároslos,
si os interesa conocer los diferentes tipos de Business Intelligence, os recomiendo
que veas este documento: http://www.sinnexus.com/business_intelligence/sistemas_soporte_decisiones.aspx
¿Cuáles son las partes que compone un sistema de Business
Intelligence? La parte más importante es el Datawarehouse, es la base
de datos donde se alojan todos los datos que utiliza la empresa, en este lugar
se depuran y trabajan dichos datos para ofrecer información y conocimiento a
gran velocidad. Otra parte importante, que a veces está incluido en el propio
Datawarehouse, son los Datamark, son las bases de datos con información
empresarial específica, puede obtener los datos de forma externa o del
Datawarehouse.
Si deseáis obtener más información con respecto al
Datawarehouse, su implantación, su construcción, su evolución, etc. Podéis acceder
a este documento PDF: https://dl.dropboxusercontent.com/u/50082027/dw0.pdf
Y lo más importante,
¿qué puede aportar un sistema de Business Intelligence a una empresa?
Recordemos que una empresa mediana o grande, maneja una gigantesca
cantidad de datos, y para tomar una decisión, deben tener muy en cuenta todos ellos,
ya que un pequeño error, puede ocasionar graves pérdidas económicas
o de prestigio.

Está claro, en vistas a lo anterior, que los sistemas de
Business Intelligence pueden ser un gran “salvavidas” para las empresas. Tener
toda la información interconexionada entre sí y almacenada en un mismo
lugar, ayuda a la hora de tomar decisiones. Estas son las grandes ventajas que
observo para las empresas que usan estos sistemas de tomas de decisiones:
 |
| El futuro del Business Intelligence |
- Es posible tener acceso y control a todos los datos e información de la empresa, en función a los permisos del usuario.
- La información siempre se encuentra actualizada, permitiendo tomar decisiones adecuadas en cualquier momento.
- Es posible crear simulaciones, lo que permite adelantarse a sucesos o tomar alternativas para evitar algún tipo de problema. Por ejemplo, si hay una bajada brutal de ingresos o si aumenta el I.V.A, etc.
- Se crea una unión entre todos los departamentos, lo que permite mejorar las relaciones entre los datos y el personal de la empresa.
- La recogida de datos se hace forma automática, ahorrando mucho tiempo a la empresa y asegurándose que los datos sean correctos, no hay errores humanos.
Ahora, veamos algunos
ejemplos reales donde se utiliza estos sistemas de toma de decisiones:
Caso 1: Una empresa de conservados maneja un
presupuesto superior a 100 millones de euros y tiene más de 500 empleados. En
verano y en diciembre es cuando se producen las mayores ventas. Por medio de un
sistema Business Intelligence han logrado mejorar un 10% su rentabilidad económica,
a través de mejoras en su capacidad logística y de almacenaje.
Caso 2: Una cadena de supermercados, con el fin de
mejorar sus ventas y atraer a los clientes con mayor capital, utilizó un
sistema Business Intelligence para analizar los datos de los clientes.
Descubrieron, por medio de este sistema, que los gustos de las personas
variaban mucho en función de su ubicación geográfica, y lo utilizaron para
fidelizar con sus clientes.
Caso 3: Una peluquería estaba buscando un día de la
semana para cerrar su negocio y poder descansar perdiendo el menor capital
posible. Para buscar el día, decidieron utilizar un sistema de toma de decisiones
utilizando los datos que habían recopilado en su sistema de citas. Se dieron
cuenta que Lunes tenían gran facturación y decidieron que el Martes era el día
más adecuado para ello.
Estos ejemplos los he extraído de la siguiente página web: http://www.sinnexus.com/business_intelligence/ejemplos.aspx.
Además, hay otros casos que también podéis ver en dicha web.
En cuanto a empresas que ofrece estos servicios de Business
Intelligence, hay dos plataformas que destacan sobre el resto: Oracle
Enterprise Performance Management and Business Intelligence
(perteneciente a Oracle) y Cognos Business Intelligence (perteneciente a
IBM). Podéis ver información de ambas plataformas en estas páginas webs: http://www.oracle.com/es/solutions/business-intelligence/index.html
Para finalizar, me gustaría comentaros que estos sistemas de
toma de decisiones me parecen muy adecuados para gestionar la enorme cantidad
de datos que puede tener una empresa u organismo. Su velocidad y su capacidad
de gestionar datos muy diversos me parecen sus dos grandes puntos fuertes. Puede
que estos sistemas solo se utilicen para grandes empresas, pero pienso que podría
ser interesante que los usuarios no técnicos podamos, en el futuro, disponer de
sistemas similares para organizar nuestros datos y ahorrarnos muchos
“quebraderos de cabeza” cuando tenemos algunos problemas, especialmente
económicos.
Por último, si deseáis estar informados de las últimas
novedades con respecto al Business Intelligence, podéis acceder a este blog: http://www.businessintelligence.info/,
donde aparecen muchas noticias, mejoras en sus sistemas, comparativas, etc. (PD:
He visto que hace bastante tiempo que no añaden nuevas entradas al blog, no sé
si el blog estará abandonado o no, en cualquier caso, los artículos que
aparecen en él son muy interesantes).