Caso 5 – Recuperación de la información

En el apartado anterior del blog, estuvimos hablando del
funcionamiento de los buscadores, así como algunas técnicas que os ayudarán a
buscar la información que deseéis en la web. En resumen, aprendimos que los
buscadores nos muestran en la pantalla de nuestros dispositivos los resultados
más aproximados a las palabras que hemos escrito en su barra de búsqueda. A
priori puede parecer muy sencillo el funcionamiento de los buscadores, aunque
seguro que sospecháis que esto no es del todo cierto. Entonces… ¿Cómo
funcionan los buscadores? ¿Qué es lo que hacen para mostrarnos las web
en nuestros dispositivos en pocos segundos?
En este apartado, intentaré responderos a estas cuestiones, centrando
la importancia en el proceso que utilizan los buscadores para “coger la información de la red” y
mostrarla en nuestro equipo. Este proceso se conoce como recuperación de la
información. Antes de empezar a trabajar este concepto, sería recomendable definir
dicho concepto de la mano de un profesional en este campo.
 |
| ¿Cómo recuperamos información? |
¿Qué es la recuperación de la información? Como dice SALTON, G. 1989. Automatic Text Processing:
The Transformation, Analysis, and Retrieval of Information by Computer.
Addison-Wesley: “Un sistema de recuperación de información procesa archivos
de registros y peticiones de información, e identifica y recupera de los
archivos ciertos registros en respuesta a las peticiones de información”.
Este concepto y/o proceso puede resultar muy complejo de
entender, yo mismo he tenido dificultades para lograr comprender este proceso.
Por eso, he decidido utilizar una estrategia sencilla, que utilizamos habitualmente
en el campo de la enseñanza, para lograr enseñaros este proceso de manera fácil
y amena.
Para ello voy a utilizar el método deductivo, que
consiste en explicar un conocimiento partiendo de sus aspectos más generales
para llegar a aspectos más específicos. Partiré de algunos ejemplos muy simples,
que poco tienen que ver con la informática, para que “visualicéis” el concepto
de recuperación de información, hasta llegar a aspectos más técnicos de los
métodos de recuperación.
¿Qué se entiende por “recuperar
información”?
Vamos a utilizar la imaginación un momento, pongamos que
tenemos en nuestra casa una gran estantería que en su interior hay muchos
cajones con cartelitos. En cada cartel del cajón aparece el nombre de los
objetos que habrá en su interior. Imaginemos que nos piden que cojamos un vaso.
¿Qué es lo que haríamos, teniendo en cuenta que no sabemos su localización?
Muy sencillo, habríamos el armario, buscaríamos en los carteles el nombre de
vasos, abriríamos su cajón correspondiente y obtendríamos nuestro preciado objeto.

La finalidad de este simple ejemplo es enseñaros el concepto
que vamos a trabajar con detalle más adelante. Con este ejemplo, hemos aprendido
que “recuperar” consiste en buscar objetos
que teníamos almacenados en un sitio para traerlos de vuelta con nosotros.
Ahora, vamos a extrapolar el ejemplo anterior en el “mundo”
informático. Que en cierto modo, si lo vemos de un modo muy general, no es
tan diferente. De momento nos vamos a olvidar de Internet, de bases de datos,
de buscadores, etc., donde la cosa se
complica bastante, y vamos a pensar solamente
en el sistema que utiliza nuestro ordenador para guardar archivos, así como sus
buscadores propios.
 |
| Sistemas de carpetas en Linux |
Nuestro ordenador utiliza un sistema de carpetas y
subcarpetas (suponiendo que hablamos de Windows o Ubuntu, desconozco si en
otros sistemas operativos este sistema es similar) para guardar nuestras fotos,
música, vídeos y documentos. Partiendo del ejemplo anterior, tenemos nuestro
armario, llamado “C”, y dentro de él encontramos más armarios llamados “vídeos”,
“fotos”, “documentos” y “música”, y dentro de música encontramos cajones con
nombres de grupos musicales.
Nuestro ordenador funciona igual manera para guardar los
archivos, aunque en este caso, somos nosotros los que decidimos el nombre de
cada carpeta (salvo las carpetas especiales pertenecientes al sistema operativo).
Por tanto, si utilizamos nuestro buscador (en caso de Windows con pulsa las
teclas: Windows + f) y escribimos un nombre de carpeta o archivo. El ordenador
buscará en el disco duro y nos mostrará los archivos que tengan dicho nombre y
nos traerá los resultados recuperados.
Hasta aquí parece fácil de entender… ¿no? De momento parece bastante
sencillo ya que solo estamos trabajando en un disco duro (un mismo lugar),
ahora bien, cuando utilizamos un buscador web, ¿Qué es lo que realmente
hace?
¿Cómo funciona la
recuperación de la información en la red?
En este caso el proceso es más complejo, ya que los archivos
que buscamos no se encuentran en un simple disco duro como sucedía anteriormente,
sino en millones y millones de discos duros que hay en los ordenadores
personales y servidores conectados a la red.
 |
| Servidores donde se almacena la información de las Webs |
Dicho de manera más sencilla, cuando buscamos algún dato o
información en Internet se producen los siguientes pasos: se escriben en el recuadro del buscador
una serie de palabras; el ordenador se conectará a los servidores
donde se aloje el buscador y por medio de una serie de técnicas y métodos (que
más adelante hablaremos) se compararán los datos que hemos introducido
en el buscador con los datos alojados en los servidores para ofrecernos una
adecuada respuesta; una vez seleccionados los datos más probables se envían
por la red hasta nuestro dispositivo. Todo este proceso se realiza en pocos
segundos.
¿Pueden los ordenadores almacenar tantos datos en sus
servidores que permitan comparar nuestras búsquedas? Sería muy laborioso
para las empresas almacenar tantos datos, por tanto, lo que hacen habitualmente
es almacenar sus datos en bases de datos para realizar más sencillas las
búsquedas. Este dibujo puede ilustraros el funcionamiento de este proceso.
 |
| Ejemplo de sistema de recuperación con bases de datos |
Voy a poneros un ejemplo práctico para que lo entendáis mejor.
Imaginemos que queremos averiguar si nuestro número de lotería es acertado.
Para ello, entramos en la siguiente web: “http://www.loteriasyapuestas.es/es/loteria-nacional”
y escribimos en el recuadro que aparece a la izquierda nuestro número, la serie
y la fracción. Esa información es redirigida al servidor donde se alija dicha
web. Después, se abre una aplicación en esa web que permite buscar en la base
de datos los datos que hemos introducido y ofrecer una respuesta adecuada. Para
finalizar, la información vuelve al
servidor de la red y se muestra en la pantalla de nuestro dispositivo.
En esta web aparece de forma muy simplificada el proceso que
os acabo de contar:
¿Qué sucede dentro de
los buscadores para qué puedan ofrecernos las webs que deseemos?
Como ya conocéis gracias al apartado anterior del blog, los
buscadores son herramientas capaces de mostrarlos las webs más adecuadas según
nuestra petición de búsqueda. Este proceso no es tan mágico como pueda parecer,
lo que realmente ocurre es que los buscadores tienen programadas una serie de
técnicas y estrategias para lograr su
cometido. Voy a contaros los pasos que realiza Google para poder
ofrecernos sus búsquedas. Esta información la ha expuesto su propia empresa, y
en esta web podéis encontrar más información al respecto: “http://aprenderinternet.about.com/od/google/a/Como-funciona-Google.htm”

Lo primero que realiza este buscador es un rastreo (o
crawling) de muchísimas páginas webs alojadas en la red para organizarlas según
sus contenidos y otras características. Después las organiza en un índice
(proceso de indexación), donde se encuentran todas las webs listadas, ocupando
una cantidad enorme de memoria (se estima que son unos 100 Pentabytes) ordenados
según sus características. Por ejemplo, se incluye los denominados “Meta Keywords”, que son las palabras
clave que definen una página web.
En el siguiente paso, lo que hace Google es utilizar una serie
de algoritmos y fórmulas matemáticas para interpretar nuestra búsqueda
y seleccionar los posibles resultados. Dichos algoritmos se encuentran en
continuo perfeccionamiento, algunos los podemos utilizar nosotros en nuestras búsquedas,
como las funciones de autocompletado o uso de sinónimos y otros tienen que ver
con mejorar en su código fuente que no podemos ver directamente. Según el
resultado de los algoritmos, se utiliza el índice para obtener las web
adecuadas a nuestra consulta, tras haber pasado una serie de factores y
filtros.
Por último, se eliminan las páginas webs denominadas SPAM.
Aunque nos faciliten el proceso de búsqueda, los creadores
de Google no nos han desvelado su misterio, que reside los algoritmos
que utilizan para ofrecernos las webs que deseemos. Dichos algoritmos y métodos
no creo que sean relevados al público ya que google perdería su gran “as en la manga”.
 |
| Ejemplo de directorio web |
Además de los buscadores, hay otras formas de recuperar
información de la red: por medio de directorios, que son listas
organizadas y estructuradas clasificadas en categorías que permiten acceder a
información partiendo de lo general a lo
particular; metabuscadores, que permiten recuperar información de varios
motores de búsqueda, si deseáis más información os recomiendo que veáis mi
anterior entrada al blog; buscadores selectivos, que recuperan información
de bases de datos especificas; agentes inteligentes, son herramientas
que permiten localizar información de forma automática tras definir un perfil
de búsqueda y una web o base de datos donde lanzarla.
En esta web podéis encontrar más información al respecto
sobre métodos, leguajes de búsqueda, técnicas de recuperación, calidad de la
recuperación, etc.: http://www.mariapinto.es/e-coms/recu_infor.htm#ri4
¿Qué conclusiones
podemos extraer?
Algunas de las conclusiones que se pueden extraer en
relación a la recuperación de la información son las siguientes:
- El proceso de recuperación de información funciona de la siguiente manera: se define lo que vamos a buscar, se seleccionan las herramientas que utilizaremos, se realizan una serie de operaciones o algoritmos y por último, se evalúan los resultados obtenidos.
- Estos son algunos elementos que se utilizan durante la búsqueda y recuperación de la información: operadores lógicos, uso de paréntesis, truncamiento, formulación de la búsqueda en lenguaje natural, etc. A través de estos elementos el usuario se comunica con el sistema de recuperación.
- El perfecto motor de búsqueda sería capaz de entender exactamente qué es lo que quieres decir y darte exactamente lo que buscas. Aún falta mucho tiempo para que se consiga dicho propósito.
Estas conclusiones han sido extraídas con ayuda de esta
página web: http://www.monografias.com/trabajos84/recuperacion-informacion-internet/recuperacion-informacion-internet2.shtml
donde además podéis encontrar más información al respecto.
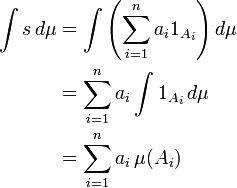 |
| Las matemáticas están muy presentes en la recuperación de la información |
Para finalizar, os voy a recomendar un extenso documento, que
podéis descargar desde mi dropbox, donde encontrareis información muy
específica sobre los métodos y técnicas de recuperación. Solo recomiendo que leáis
dicho documento las personas que os dediquéis a la informática, ya que aparecen
términos informáticos y matemáticos muy complejos de entender. Solo he
utilizado las primeras hojas de dicho documento para comprender un poco mejor
el concepto de recuperación de la información, pero el resto de información no he sido capaz de entenderla
bien, de ahí que no haya profundizado mucho en estos aspectos.
Como añadido, dado que en el PDF anterior aparecen
cuestiones complejas de entender, os recomiendo también la siguiente página web
donde aparecen definidos algunos términos y cuestiones que aparecen en el
documento:
No hay comentarios:
Publicar un comentario